플라워로드 기술 블로그 : http://blog.flowerroad.ai
Notion Link : https://flyingcorp.notion.site/Backend-AWS-Architecture-4b91609eaa7441cda0ccf06714d9948b
이 글은 2020년 1월 16일에 포스팅 되었습니다. 2022년 2월 현재는 다수의 AWS service(ex. SQS, MQ, openSearch, route53, GraphQL등등) 혹은 VPC 분리등이 적용 되어 기존 구조 혹은 서비스들의 단점이나 추가 기능들을 보완한 구조로 운영중입니다.
Overview
이전 두 포스팅인 플라워로드 시스템 아키텍처 - 사용되는 기술들 과 플라워로드 시스템 아키텍처 - 데이터 Flow 에서 대략적인 플라워로드 시스템의 구성을 살펴 봤고, 이번 포스팅에서는 플라워로드 시스템에서 사용중인 AWS services들이 어떻게 구성되어 있는지를 살펴볼 예정입니다.
💡 해당 architecture는 2018년 후반에 설계를 시작해서 구성된 내용으로 Lambda를 이용한 MSA를 target로 설계 되었습니다. 현재는 AWS의 의존성을 낮추기 위해서 K8S(Kubernetes)를 이용한 MSA를 진행중에 있습니다.
AWS services
너무 많은 service들을 사용중이기 때문에 여기에 일일이 모두 나열하기는 조금 힘든면이 있습니다.(글을 쓰고 있는 현재 모두 기억할 수 있을지도 모르겠네요...)
저희는 모든 서비스를 AWS에서 운영을 하고 있으며, computing 이나 DB, log monitoring, data analysis, ML등 외에도 source code repository도 AWS CodeCommit를 사용하며, CI/CD를 위한 tool들도 AWS CodePipiLine, AWS CodeBuild, AWS CodeDeploy를 사용하고 있습니다.
이것에 그치지 않고 개발시 VPC의 private한 환경의 접근을 위해서 (ex. AWS Aurora Serverless DB) AWS Cloud9도 사용하고 있으며, 저희 Domain의 routing을 위한 AWS Route53도 사용하고 있습니다.
물론 Data Analysis와 ML을 위한 AWS Athena, AWS SageMaker, AWS EMR, QuickSight등도 사용하고 있습니다.
해당 포스팅에서는 Data Analysis나 ML, build 환경같은 외적인 내용은 제외하고 저희 플라워로드의 서비스를 위한 AWS Service 구성만을 살펴보겠습니다.
Service Architecture Diagram

대략적인 AWS Service들의 구성을 나열한 Diagram입니다. 하나의 Diagram에 모든 내용을 포함하기에는 너무 복잡하고 여기에서 굳이 다루지 않아도 될 내용들이 있었기 때문에 생략한 내용도 있습니다.(ex. security group, E-IP, NAT, Internet GW등)
위의 Architecture Diagram은 크게 세부분으로 나뉘어서 볼수 있습니다. 스쿠터와의 communication 및 스쿠터의 데이터를 처리/저장을 담당하는 부분, 사용자 및 관리자 앱의 요청을 처리/데이터 저장을 담당하는 부분, 마지막으로 source code repository, CI/CD 부분으로 나뉘어 볼수 있습니다.
Scooters / ECS Server

앞선 포스팅에서 설명한것 처럼 스쿠터의 종류에 따라 TCP/IP socket 통신을 이용해서 연결 유지 및 데이터 송수신을 하고 있습니다. 따라서, 이를 위한 server 가 필요로 했습니다.
크게 고민하지 않고 docker image로 만들 작은 server program을 NodeJS로 구현을 하고 load balance, scale up/out 의 편의를 위해서 Network Load Balancer + AWS ECS + Fargate 를 이용하기로 했습니다. 이 당시 AWS에서 K8S를 서비스 하지 않았기 때문에 추후 K8S로 옮겨가는 것을 고려해서 docker image로 만들어서 운영을하게 되었습니다.
Network의 구성은 간략하게 Public Subnet에서 외부 포트를 하나 열어두고 Network Load Balancer를 이용해서 Private Subnet 내부의 ECS에 분산 접속 해주는 방식을 사용합니다. 당연히 하나의 Fargate가 임계점에 다다르면 ECS가 scale out방식으로 또 다른 Fargate가 생성 및 launch되고 Network Load Balancer 가 적당히 traffic을 분산해주게 됩니다.
Fargate의 아래쪽으로 화살표를 보면 Lambda와 연결되어 있는데 Fargate에서 running되는 서버는 스쿠터로부터 받은 데이터 처리를 하지 않습니다. 모든 데이터의 처리는 Lambda에게 위탁하고 처리된 데이터를 다시 스쿠터로 전달하는 역활만 합니다.
몇몇 분들이 Spring서버를 사용하지 않고 NodeJS를 사용한 이유에 대해서 궁금해 하셨는데 간략하게 설명을 드리자면,
첫째는 구현의 편의성 입니다. 많이 아시다시피 npm을 이용한 다양한 3rd party 프로그램을 이용해서 빠른 구현이 가능하고, 이렇다 보니 상대적으로 많은 시간을 투입하지 않고 구현을 완료할 수 있었습니다.
두번째로, 저사양 환경에서의 성능 확보입니다. 이 내용은 아직까지도 어떤 서버냐에 따라서 논란의 여지가 있기는 하지만 대체로 저사양환경에서 Node.JS가 더 높은 가용성을 보여주고 있습니다.
세번째로, 서비스의 특성 때문입니다. 두번째 이유와 조금 관련이 있는 내용이기는 합니다. 이 서버는 TCP/IP server이고 다수의 스쿠터가 연결되어 데이터를 주고 받고 있습니다. 그리고, 위에 잠시 언급한것과 같이 특별히 데이터를 encoding/decoding하거나 처리하지 않는 서버로서 모든 데이터의 처리는 Lambda에 위탁하고 서버는 MQTT message Broker와 비슷하게 데이터의 bridge 혹은 queue역활만 해주고 있습니다. 이렇다 보니 대부분의 작업이 I/O에 관련된 내용이고 이 I/O 또한 스쿠터 한대 기준으로 수십초에 한번씩 일어나는 정말 loose한 서버입니다. 이런 서버의 특성이 있다보니 연결된 클라이언트 마다 지속적으로 자원을 reserve하는 Spring 을 사용할 필요가 없었습니다.
App

사용자 앱과 저희 관리자들이 사용하는 앱의 서비스를 위한 부분입니다.
기본적으로 API Gateway를 통해서 요청된 내용은 AWS Cognito에 의해서 인증된 요청만 Lambda에 의해서 처리되고, Lambda는 ElastiCache(Redis), Aurora DB(MySql), DynamoDB에서 데이터를 가지고 와서 business logic를 처리한 후 적절한 응답을 반환합니다.
일반적인 Debugging 및 분석은 CloudWatch의 Log message를 이용하고, 가끔 데이터, 에러율등의 집계가 필요한 경우 Insights 를 이용하고 있습니다. X-Ray의 경우 response time을 세분화해서 분석할때 사용하기도 하는데 비용적이 면과 lambda의 실행시간에 영향을 주기 때문에 자주 사용하는 일은 없고, 특별한 목적이 있을때만 enable해서 사용합니다.
Lambda, 모든 데이터의 처리(processing, computing)는 Lambda에서합니다. 처음에는 소수의 Lambda만으로도 모두 처리가 가능했으나 지금은 Lambda Functions만 수십 수백개가 넘어가고 Lambda들의 묶음이 하나의 큰 카테고리의 service 기능을 담당하고 각각은 더 작은 단위의 service들을 처리하도록 구성되어 있습니다. 작은단위의 service들을 모두 개별 Lambda로 만들기에는 그 숫자가 너무 많아지는 문제가 있어서 주요 domain 및 category, 기능등으로 나눠서 분류되어 있습니다.
이렇게 작은 단위의 service로 구분해서 Lambda로 구성되다 보니 Business Logic를 처리하기 위해서는 마치 거미줄처럼 Lambda 에서 다른 여러 Lambda를 Invoke하는 경우가 많습니다. 이런 방식의 MSA는 Traffic에 대한 load balancing을 크게 고민할필요가 없어서 소수의 개발 및 유지보수에 매우 큰 이득이 되었습니다. 실제로 이 구성은 최초 저희가 서비스를 시작한 이래로 단 한번도 서버가 shutdown되거나 서비스가 정지되는 일이 없었습니다.
AWS SQS의 도입. 최초 외부 event 기반으로 호출되는 lambda들, 그리고 호출된 lambda에서 발생한 event에 의해서 invoke되는 여러 lambda들은 마치 EDA(Event Driven Architecture)를 연상하게 됩니다. 하지만, 이 경우 외부에서 발생한 하나의 event에 대한 처리를 파악하기가 쉽지 않게 되어 Queue를 도입해서 처리 하게 되었습니다. 처음에는 AWS MSK(Managed Streaming for Kafka) 혹은 AWS MQ 를 도입하려고 했으나 초기 스타트업의 특성상 비용의 문제도 있고, 당장 이걸 적용해서 크게 이득을 보려고 하는게 아니기 때문에 일단 AWS SQS를 이용해서 event를 처리를 해보고 괜찮으면 이후에 MSK 혹은 MQ를 적용하자 라고 생각하게 되었습니다. 그리고, 몇몇의 event에 이를 적용하고 나머지들은 기존과 같은(ex. data lake 구축을 위한 로그수집 함수 같은...) lambda에서 직접 event방식으로 invoke하도록 적용을 했습니다. 이후 대체로 외부에서 유입되는 event들은 파악이 쉽게 되도록 구성이 되었습니다.
AWS Cognito를 선택한 것은 약간의 모험이였습니다. 개발 초기 적은 resource로 많은 것을 해야하다보니 로그인, 인증에 대해서 개발을 하지 않고 Cognito의 User Pool을 사용하가로 했습니다. 때마침cognito에 User Pool기능이 추가 되었고, MFA(Multi Factor Authentication)까지 지원을 하니 크게 고민할 필요가 없었습니다.
다만 User Pool이 신규 서비스이고 아직 AWS Amplify가 선보이기 전이였기 때문에 android, ios개발에 대해서 참고할만한 reference가 없어서 자잘한 문제가 많이 발생했었습니다.(지금도....)
현재는 architecture의 모든 구성을 Lambda가 아닌 docker기반의 K8S로 전환을 위한 검토 진행중에 있습니다.
사실 현재 사용하고 있는 구성도 서비스에 크게 문제는 없으나(실제로 신규 기능 구현, 디버깅, 테스트, 유지 보수에 있어서 불편함을 느끼지 못합니다.) 모든 구성이 AWS에 너무 특화 되어 있다보니 다른 서비스(ex, GCP, Asure)로의 이전이 쉽지 않기 때문에 미래를 위해서 K8S를 검토하고 있습니다.
Repository, CI/CD
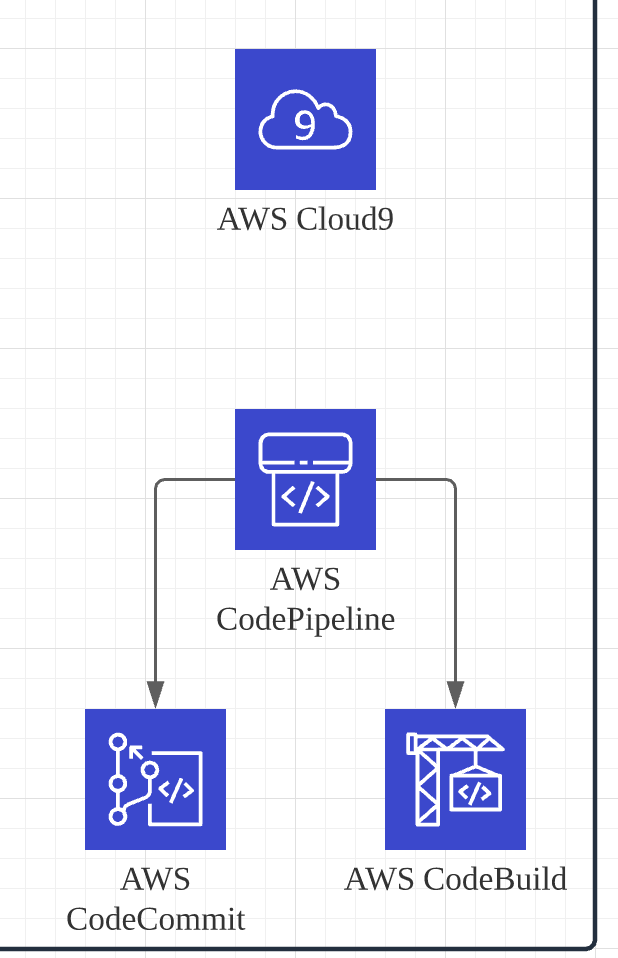
앞서 간략하게 설명한것처럼 플라워로드 Backend System은 CodePipeLine를 이용해서 Deploy됩니다.
2주단위의 스프린트를 진행하고 이에 따라 매 2주마다 CodePipiLine를 이용해서 신규 버전을 Release하고 있습니다.
CodePipiLine는 저희가 사용중인 CodeCommit를 모니터링 하고 push가 발생할 경우 자동으로 trigger됩니다. 이후 관리자의 승인이 있을 경우 CodeBuild를 통해서 빌드 및 unit test를 진행하고 이상이 없는 경우 deploy합니다.
API Gateway와 Lambda의 deploy를 좀더 편리하게 하기 위해서 CodeBuild에서 코드에 문제가 없을 경우 serverless framework을 이용해서 모든 API Gateway와 Lambda를 deploy 합니다. 이는 개별로 일일이 배치를 하기위한 수고를 많이 덜어주고 있습니다. (다만 lambda, API 가 많아지면 여러개의 serverless.yml파일로 분리해서 이용해야 합니다.)
사용중인 모든 AWS service에 대해서 CodePipeLine이 Deploy하는 것은 아닙니다. 위에서 언급한것 처럼 Lambda, API Gateway, CouldWatch Event Rules에 대해서만 deploy작업을 진행합니다. 이유는 2주마다 진행된 개발내용이 다른 infra적인 AWS service에는 거의 영향을 주지않기 때문입니다. (예를들면 Aurora DB, VPC등 기본적인 infra에 대한 구성은 terraform에 의해서 deploy가 이루어지고 이는 거의 변경할 내용이 없습니다.)
마치며...
글을 쓰면서 최대한 내용을 압축하려고 하다보니 현업에 있는 개발자 혹은 서비스 이용을 고려하고 있는 분들에게는 크게 도움이 되지 않을 수 있겠다 라는 생각을 했습니다. 현재 저희가 사용하고 있는 서비스도 많고 각각의 서비스를 선택하게 된 이유들도 많다보니 이 포스팅에서 세부 내용을 모두 다룰 수는 없었고 대략적인 그림만 다룬것 같네요. 기회가 되면 주요 서비스에 대해서 좀더 상세한 내용(Lambda deploy 방법, 예제 등)이나 구성하면서 고려한 code architecture 등도 포스팅하겠습니다.
'개발 > backend' 카테고리의 다른 글
| [Backend] 쿠버네티스(K8S)를 시작해보자(1) - 이론편 (0) | 2022.03.06 |
|---|---|
| [AWS] AWS RDS - MySQL vs Aurora (0) | 2022.02.27 |
| [Backend] 공유 스쿠터 서비스 - 플라워로드 시스템 아키텍처 사용 기술들 (0) | 2022.02.23 |
| [Backend] 공유 스쿠터 서비스 - 플라워로드 시스템 아키텍쳐 데이터 FloW (0) | 2022.02.23 |
| [Backend] AWS WebSocket 적용하기 (Feat. APIGateway, Lambda) (0) | 2022.01.28 |